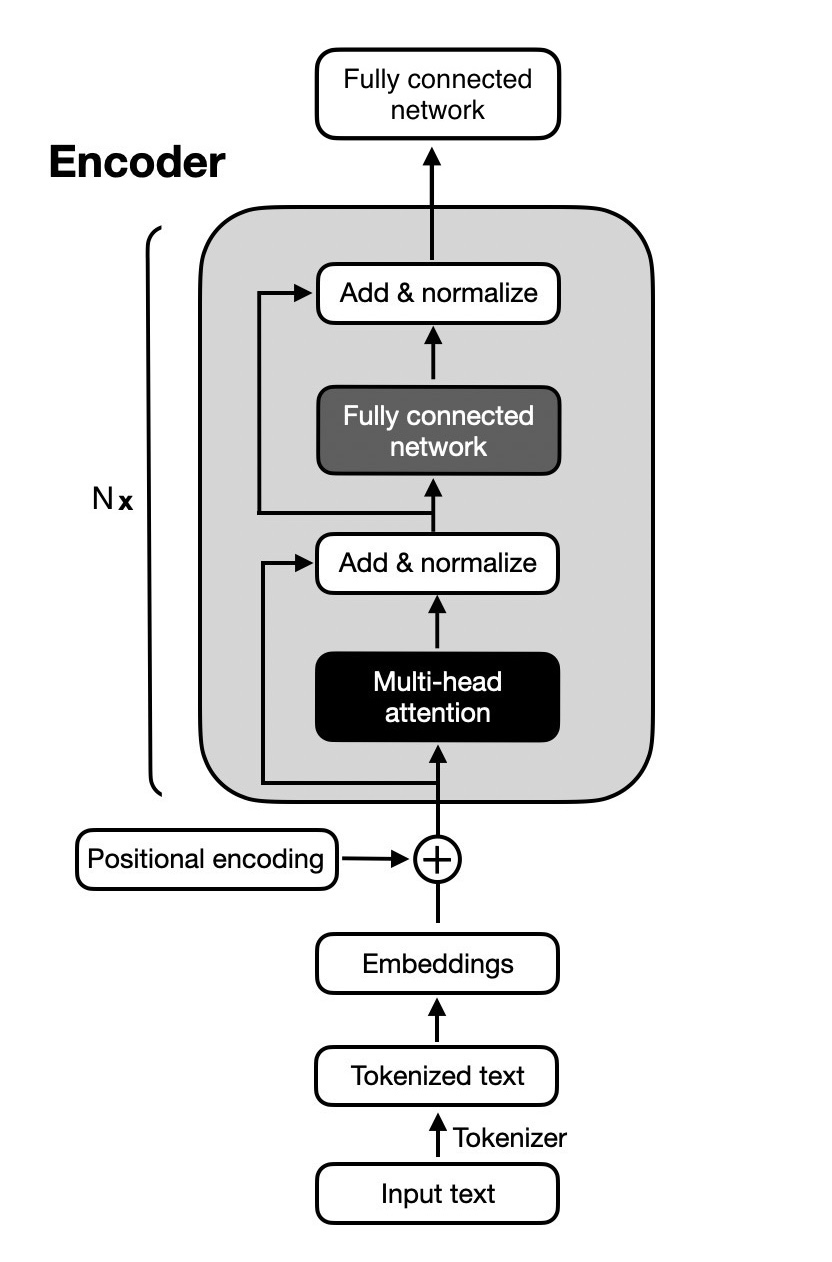
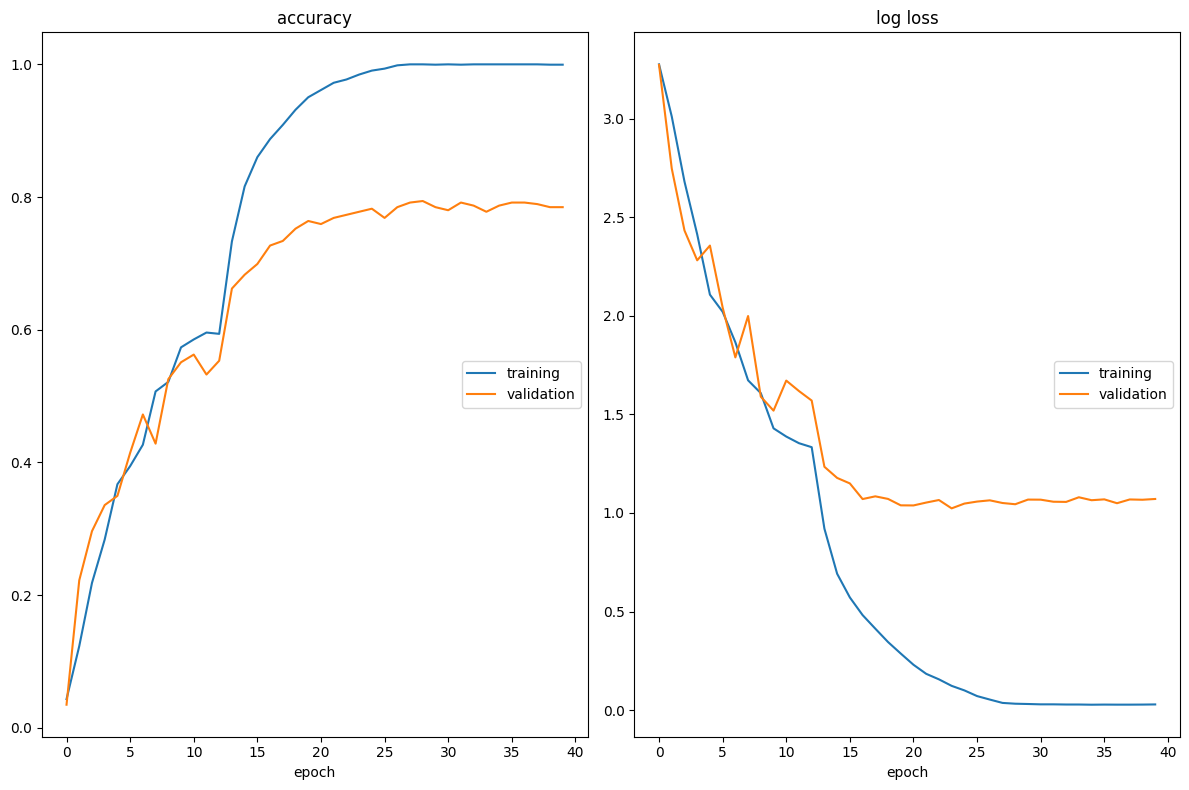
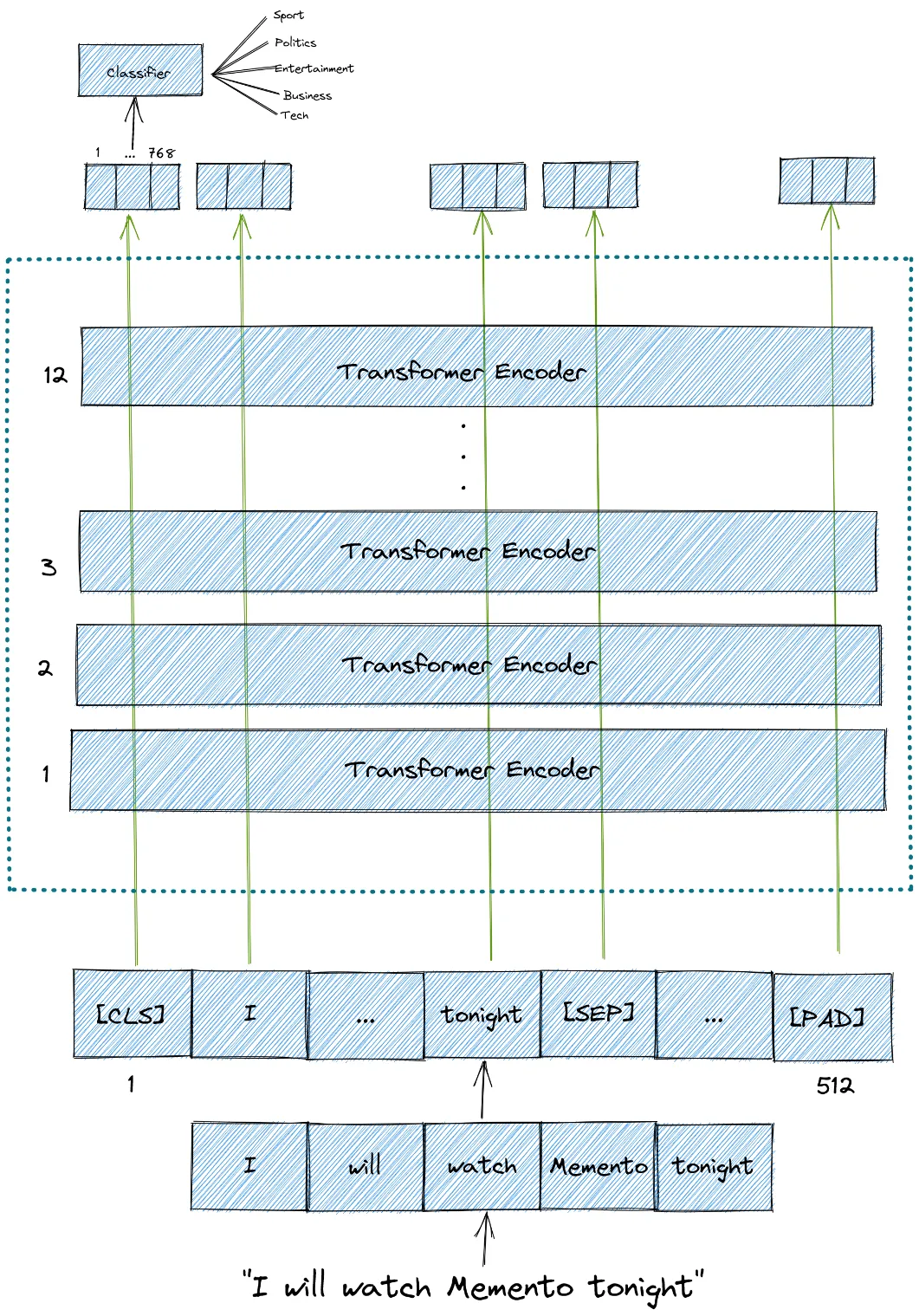
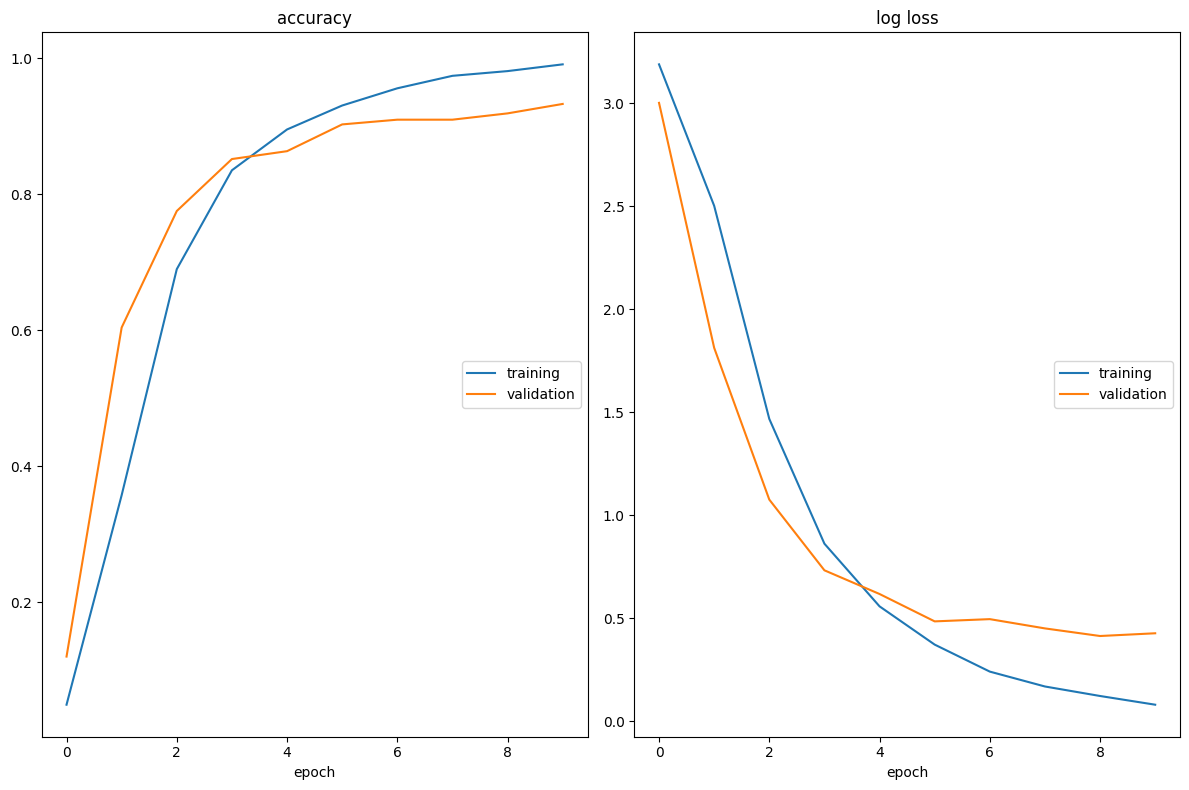
class EmbeddingLayer(nn.Module):
def __init__(self, vocab_size: int, d_model: int):
super().__init__()
# Dimensions of embedding layer
self.embedding = nn.Embedding(vocab_size, d_model)
# Embedding dimension
self.d_model = d_model
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)
class PositionalEmbedding(nn.Module):
def __init__(self, vocab_size: int, d_model: int, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
# Initialize positional embedding matrix (vocab_size, d_model)
pe = torch.zeros(vocab_size, d_model)
# Positional vector (vocab_size, 1)
position = torch.arange(0, vocab_size).unsqueeze(1)
# Frequency term
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000) / d_model))
# Sinusoidal functions
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# Add batch dimension
pe = pe.unsqueeze(0)
# Save to class
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
class LayerNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-6):
super().__init__()
# Learnable parameters
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.ones(d_model))
# Numerical stability in case of 0 denominator
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# Linear combination of layer norm with parameters gamma and beta
return self.gamma * (x - mean) / (std + self.eps) + self.beta
class ResidualConnection(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1):
super().__init__()
# Layer normalization for residual connection
self.norm = LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x1, x2):
return self.dropout(self.norm(x1 + x2))
class FeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int = 2048, dropout: float = 0.1):
super().__init__()
# Linear layers and dropout
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.linear2(self.dropout(F.relu(self.linear1(x))))
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float =0.1, qkv_bias: bool = False, is_causal: bool = False):
super().__init__()
assert d_model % num_heads == 0, "d_model is not divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.dropout = dropout
self.is_causal = is_causal
self.qkv = nn.Linear(d_model, 3 * d_model, bias=qkv_bias)
self.linear = nn.Linear(num_heads * self.head_dim, d_model)
self.dropout_layer = nn.Dropout(dropout)
def forward(self, x, mask=None):
batch_size, seq_length = x.shape[:2]
# Linear transformation and split into query, key, and value
qkv = self.qkv(x) # (batch_size, seq_length, 3 * embed_dim)
qkv = qkv.view(batch_size, seq_length, 3, self.num_heads, self.head_dim) # (batch_size, seq_length, 3, num_heads, head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4) # (3, batch_size, num_heads, seq_length, head_dim)
queries, keys, values = qkv # 3 * (batch_size, num_heads, seq_length, head_dim)
# Scaled Dot-Product Attention
context_vec = F.scaled_dot_product_attention(queries, keys, values, attn_mask=mask, dropout_p=self.dropout, is_causal=self.is_causal)
# Combine heads, where self.d_model = self.num_heads * self.head_dim
context_vec = context_vec.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
context_vec = self.dropout_layer(self.linear(context_vec))
return context_vec
class EncoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, hidden_dim: int, dropout: float = 0.1):
super().__init__()
# Multi-head self-attention mechanism
self.multihead_attention = MultiHeadAttention(d_model, num_heads, dropout)
# First residual connection and layer normalization
self.residual1 = ResidualConnection(d_model, dropout)
# Feed-forward neural network
self.feed_forward = FeedForward(d_model, hidden_dim, dropout)
# Second residual connection and layer normalization
self.residual2 = ResidualConnection(d_model, dropout)
def forward(self, x, mask=None):
x = self.residual1(x, self.multihead_attention(x, mask))
x = self.residual2(x, self.feed_forward(x))
return x
class EncoderStack(nn.Module):
def __init__(self, d_model: int, num_heads: int, hidden_dim: int, num_layers: int, dropout: float = 0.1):
super().__init__()
# Stack of encoder layers
self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, hidden_dim, dropout) for _ in range(num_layers)])
def forward(self, x, mask=None):
for layer in self.layers:
x = layer(x, mask)
return x
class TransformerClassifier(nn.Module):
def __init__(self, vocab_size: int, d_model: int, num_heads: int, hidden_dim: int, num_layers: int, out_features: int, dropout: float = 0.1):
super().__init__()
self.embedding = EmbeddingLayer(vocab_size, d_model)
self.positional_embedding = PositionalEmbedding(vocab_size, d_model, dropout)
self.encoder = EncoderStack(d_model, num_heads, hidden_dim, num_layers, dropout)
self.classifier = nn.Linear(d_model, out_features)
def forward(self, x, mask=None):
x = self.embedding(x)
x = self.positional_embedding(x)
x = self.encoder(x, mask)
x = x.mean(dim=1)
x = self.classifier(x)
return x